
The Apriori Algorithm in Python. Expanding Thor’s fan base
In this article, I will go over a simple use case for the Apriori model.
Credits:
- Usman Malik https://stackabuse.com/association-rule-mining-via-apriori-algorithm-in-python/ I love the way he explains data science in his blog. Here I followed his structure but modified the data, changed his elegant print in a data frame that you can download or use in a workflow, added Alteryx scripts if you would like to run this code as part of an end-to-end Alteryx workflow that you want to put in production.
- Hadelin de Ponteves and Kirill Eremenko for their course Machine Learning from A to Z, this Apriori example it’s in their course as well
- My wonderful Data Engineer Shokat Ali
Please Note: the movie data are completely random, they do not represent any real-life dataset.
The Jupyter notebook and the dataset are here: https://github.com/pirandello/apriori
Association Rules are used to identify underlying relations between different items. Take the example of a Movie Platform where customers can rent or buy movies. Usually, there is a pattern in what the customers buy. There are clear patterns, for instance, the Super Hero theme, or the Kids category.
More profit can be generated if the relationship between the movies can be identified.
If movie A and B are frequently bought together, this pattern can be exploited to increase profit
People who buy or rent one of these two movies can be nudged into renting or buying the other one, via campaigns or suggestions within the platform.
We are today very familiar with these recommendation engines on Netflix, Amazon, to name the most prominent.
The Apriori Algorithm
The Apriori Algorithm falls in the Association Rule category.
Theory of Apriori Algorithm
There are three major components of the Apriori algorithm:
- Support
- Confidence
- Lift
Let’s analyze each component. Before we start, we need to agree on the time window that makes business sense. In our example, it could be all the movies purchased or rented by individual customers in a month or a year.
Support
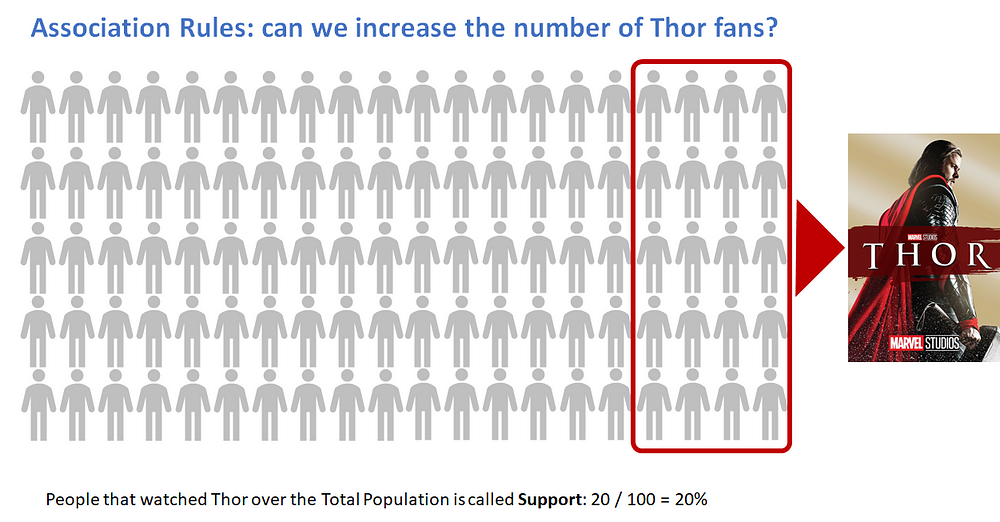
Support in our use case refers to the popularity of a movie and it is calculated as the number of times a movie is watched divided by the total number of transactions.
For instance if out of a total population of 100 people, 20 watched Thor, the support can be calculated as:
Support(Thor) = (Transactions containing The Thor)/(Total Transactions)
Support(Thor) = 20/100 = 20%
Confidence
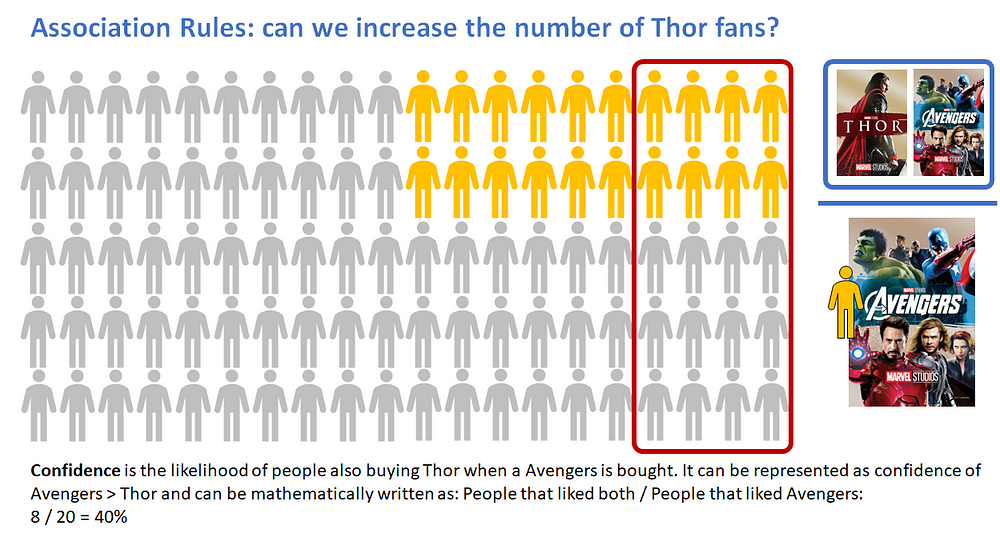
Confidence refers to the likelihood of people also buying Thor if they watch the Avengers. It can be calculated by finding the number of transactions where Thor and Avengers were bought together, divided by the total number of transactions where Avengers were purchased.
Confidence(Avengers → Thor) = (Transactions containing both (Thor and The Avengers))/(Transactions containing Avengers)
If we had 8 transactions where customers watched Thor and Avengers, while in 20 transactions, Avengers is purchased or rented, then we can find the likelihood of buying Thor if Avengers is bought.
Confidence(Avengers → Thor) = 8/20 = 40%
Lift
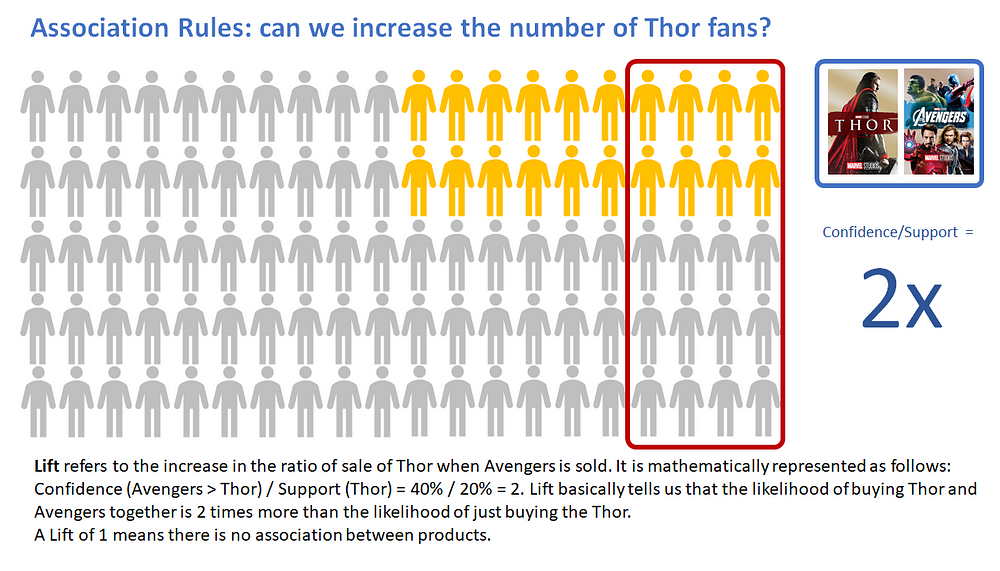
Lift(Thor -> Avengers) refers to the increase in the ratio of the sale of Thor when Avengers is sold. It can be calculated by dividing Confidence(Thor -> Avengers) divided by Support(Thor). Mathematically it can be represented as:
Lift(Thor → Avengers) = (Confidence (Avengers → Thor))/(Support (Thor))
It can be calculated as:
It can be calculated as:
Lift(Lift → Avengers) = 40%/20% = 2
Lift tells us that the likelihood of buying a Thor and Avengers together is twice as much as the likelihood of just buying the Thor.
A Lift of 1 means there is no association between products. A Lift greater than 1 means that products are more likely to be purchased together.
Steps Involved in Apriori Algorithm
For large sets of data, there can be hundreds of items in hundreds of thousands of transactions. The Apriori algorithm tries to extract rules for each possible combination of items. For instance, Lift can be calculated for item 1 and item 2, item 1 and item 3, item 1 and item 4 and then item 2 and item 3, item 2 and item 4 and then combinations of items e.g. item 1, item 2 and item 3; similarly item 1, item2, and item 4, and so on.
This algorithm can be extremely slow due to the number of combinations. To speed up the process, we need to perform the following steps:
- Set a minimum value for support and confidence. This means that we are only interested in finding rules for the items that have certain default existence (e.g. support) and have a minimum value for co-occurrence with other items (confidence).
- Extract all the subsets having a higher value of support than the minimum threshold.
- Select all the rules from the subsets with a confidence value higher than the minimum threshold.
- Order the rules by descending order of Lift.
Implementing Apriori Algorithm with Python
In this section, we will use the Apriori algorithm to find rules that describe associations between different products given 7500 transactions over the course of a month. The dataset of movies is randomly picked, these are not real data.
Another interesting point is that we do not need to write the script to calculate support, confidence, and lift for all the possible combinations of items. We will use an off-the-shelf library where all of the code has already been implemented.
The library apyori. Use the following command in your environment: pip install apyori
If you are planning to embed this python code inside an Alteryx workflow (2018.3 and up) uncomment the following lines

Import the Libraries
The first step, as always, is to import the required libraries. Execute the following script to do so.
You may need to install the apyori module in your Python environment from your Terminal: pip install apyori

Importing the Dataset
Now let’s import the dataset and see what we’re working with. This module doesn’t want headers, so set header = None

Use the following script if you are reading data inside an Alteryx workflow

Now we will use the Apriori algorithm to find out which items are commonly sold together, so that store owners can take action to place the related items together or advertise them together in order to have increased profit.
Data Preprocessing
The Apriori library we are going to use requires our dataset to be in the form of a list of lists, where the whole dataset is a big list and each transaction in the dataset is an inner list within the outer big list. Currently, we have data in the form of a pandas data frame. To convert our pandas data frame into a list of lists, execute the following script:

Applying Apriori
We can now specify the parameters of the apriori class.
- The List
- min_support
- min_confidence
- min_lift
- min_length (the minimum number of items that you want in your rules, typically 2)
Let’s suppose that we want only movies that are purchased at least 40 times in a month. The support for those items can be calculated as 40/7500 = 0.0053. The minimum confidence for the rules is 20% or 0.2. Similarly, we specify the value for lift as 3 and finally, min_length is 2 since we want at least two products in our rules. These values are mostly just arbitrarily chosen and they need to be fine-tuned empirically.
Execute the following script:

In the second line here we convert the rules found by the apriori class into a list since it is easier to view the results in this form.
Viewing the Results Let’s first find the total number of rules mined by the apriori class. Execute the following script:

The script above should return 32. Each item corresponds to one rule.
Let’s print the first item in the association_rules list to see the first rule. Execute the following script:
The output should look like this:

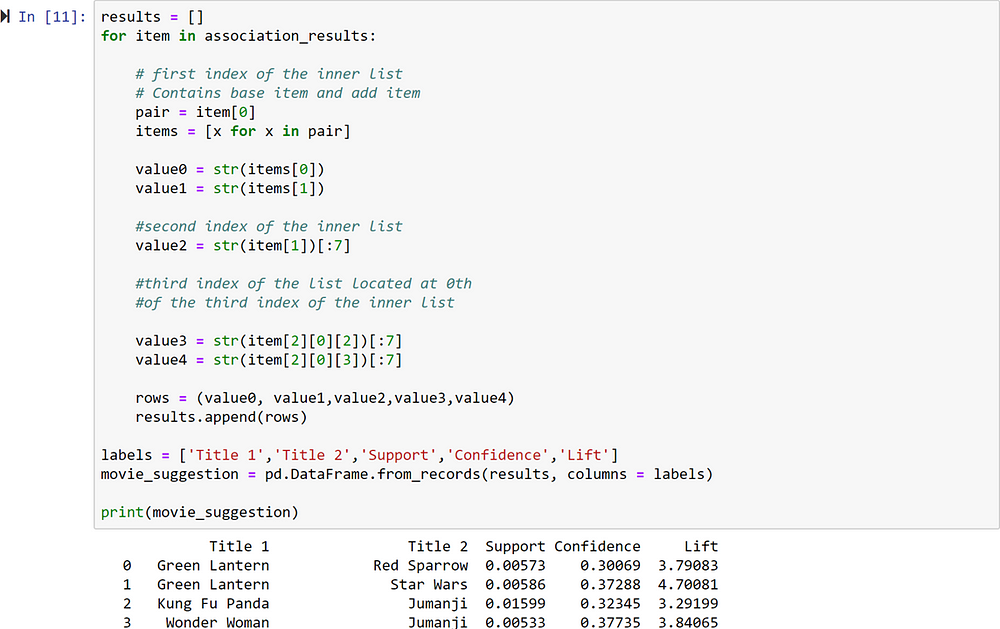
The first item in the list is a list itself containing three items. The first item of the list shows the movies in the rule.
For instance, from the first item, we can see that Red Sparrow and Green Lantern are commonly bought together.
The support value for the first rule is 0.0057. This number is calculated by dividing the number of transactions containing Red Sparrow divided by the total number of transactions. The confidence level for the rule is 0.3006 which shows that out of all the transactions that contain Red Sparrow, 30% of the transactions also contains Green Lantern. Finally, the lift of 3.79 tells us that Green Lantern is 3.79 times more likely to be bought by the customers who buy Red Sparrow compared to the default likelihood of the sale of Green Lantern.
The following script displays the rule in a data frame in a much more legible way:
Use this script if you want to output in Alteryx

Conclusion
Association rule mining algorithms such as Apriori are very useful for finding simple associations between our data items. They are easy to implement and easy to explain to initiate a conversation with your marketing and sales team. There are more complex algorithms such as collaborative filtering used by YouTube to name just one.
The Business Problem always drives how the algorithm will be implemented.
In eCommerce, you may look at transaction by transaction.
In video streaming, you may want to look at movies watched in a week or a month (you can also run multiple apriori depending on the RFM segmentation of your customers (RFM stands for Recency Frequency Monetary analysis).
In Education, you may look at academic years, what choices a student makes in his/her first academic year? Which Core and Elective Programs will he/she choose? In complex scenarios such as the Education Business, you also need to consider that there are few fixed choices for students, as courses and material are decided by faculty members. You can evaluate if suggestions can be made on the eCommerce platform (once you match the student to the institution and you own multiple titles offered at the institution for a given academic year). On the Sales side, you may want to consider combined go-to-market activities to bundle titles together that may belong to one or more product managers. Furthermore, you may want to differentiate your offering whether or not you are already selling both titles in an institution or just one.
The complexity of business problems and scenarios determines the optimal path to the right implementation strategy that will need to be fine-tuned over time, along with the underlying algorithms.
This is the Apriori analysis output in Tableau
This is the Apriori analysis output in Tableau



Comments
Post a Comment